На уроке рассматривается работа с файлами в Питон: текстовые и бинарные файлы, запись в файл и чтение из файла
Содержание:
- Файлы в Python
- Работа с текстовыми файлами в Питон
В целом различают два типа файлов (и работы с ними):
- текстовые файлы со строками неопределенной длины;
- двоичные (бинарные) файлы (хранящие коды таких данных, как, например, рисунки, звуки, видеофильмы);
Этапы работы с файлом:
- открытие файла;
- режим чтения,
- режим записи,
- режим добавления данных.
- работа с файлом;
- закрытие файла.
В python открыть файл можно с помощью функции open с двумя параметрами:
- имя файла (путь к файлу);
- режим открытия файла:
- «r» – открыть на чтение,
- «w» – открыть на запись (если файл существует, его содержимое удаляется),
- «a» – открыть на добавление.
В коде это выглядит следующим образом:
Fin = open ( "input.txt" ) Fout = open ( "output.txt", "w" ) # работа с файлами Fout.close() Fin.close()
Работа с текстовыми файлами в Питон
- Чтение из файла происходит двумя способами:
- построчно с помощью метода readline:
- метод read читает данные до конца файла:
- Для получения отдельных слов строки используется метод split, который по пробелам разбивает строку на составляющие компоненты:
- способ:
- способ:
- В python метод write служит для записи строки в файл:
- Запись в файл можно осуществлять, используя определенный
шаблон вывода. Например: - Аналогом «паскалевского» eof (если конец файла) является обычный способ использования цикла while или с помощью добавления строк в список:
- подходящий способ для Python:
файл input.txt:
1
2
3
str1 = Fin.readline() # str1 = 1 str2 = Fin.readline() # str2 = 2
файл input.txt:
1
2
3
str = Fin.read() ''' str = 1 2 3 '''
str = Fin.readline().split() print(str[0]) print(str[1])
Пример:
В файле записаны два числа. Необходимо суммировать их.
файл input.txt:
12 17
ответ:
27
✍ Решение:
Fin = open ( "D:/input.txt" ) str = Fin.readline().split() x, y = int(str[0]), int(str[1]) print(x+y)
... x, y = [int(i) for i in s] print(x+y)
* Функция int преобразует строковое значение в числовое.
Fout = open ( "D:/out.txt","w" ) Fout.write ("hello")
Fout.write ( "{:d} + {:d} = {:d}n".format(x, y, x+y) )
В таком случае вместо шаблонов {:d} последовательно подставляются значения параметров метода format (сначала x, затем y, затем x+y).
while True: str = Fin.readline() if not str: break
Fin = open ( "input.txt" ) lst = Fin.readlines() for str in lst: print ( str, end = "" ) Fin.close()
for str in open ( "input.txt" ): print ( str, end = "" )
Задание Python 9_1:
Считать из файла input.txt 10 чисел (числа записаны через пробел). Затем записать их произведение в файл output.txt.
Рассмотрим пример работы с массивами.
Пример:
Считать из текстового файла числа и записать их в другой текстовый файл в отсортированном виде.
✍ Решение:
- Поскольку в Python работа с массивом осуществляется с помощью структуры список, то количество элементов в массиве заранее определять не нужно.
- Считывание из файла чисел:
- Сортировка.
- Запись отсортированного массива (списка) в файл:
- Или другой вариант записи в файл:
lst = [] while True: st = Fin.readline() if not st: break lst.append (int(st))
Fout = open ( "output.txt", "w" ) Fout.write (str(lst)) # функция str преобразует числовое значение в символьное Fout.close()
for x in lst: Fout.write (str(x)+"n") # запись с каждой строки нового числа
Задание Python 9_2:
В файле записаны в целые числа. Найти максимальное и минимальное число и записать в другой файл.
Задание Python 9_3:
В файле записаны в столбик целые числа. Отсортировать их по возрастанию суммы цифр и записать в другой файл.
Рассмотрим на примере обработку строковых значений.
Пример:
В файл записаны сведения о сотрудниках некоторой фирмы в виде:
Иванов 45 бухгалтер
Необходимо записать в текстовый файл сведения о сотрудниках, возраст которых меньше 40.
✍ Решение:
- Поскольку сведения записаны в определенном формате, т.е. вторым по счету словом всегда будет возраст, то будем использовать метод split, который разделит слова по пробелам. Под номером 1 в списке будет ити возраст:
- Более короткая запись будет выглядеть так:
- Программа выглядит так:
- Но лучше в стиле Python:
st = Fin.readline() data = st.split() stAge = data[1] intAge = int(stAge)
st = Fin.readline() intAge = int(st.split()[1])
while True: st = Fin.readline() if not s: break intAge = int (st.split()[1])
for st in open ( "input.txt" ): intAge = int (st.split()[1]) if intAge < 40: Fout.write (st)
Задание Python 9_4:
В файл записаны сведения о детях детского сада:
Иванов иван 5 лет
Необходимо записать в текстовый файл самого старшего и самого младшего.

Михаил Свинцов
автор курса «Full-stack веб-разработчик на Python»
Взаимодействие с файловой системой позволяет хранить информацию, полученную в результате работы программы. Михаил Свинцов из SkillFactory расскажет о базовой функциональности языка программирования Python для работы с файлами.
Основа для работы с файлами — built-in функция open()
open(file, mode="rt")Эта функция имеет два аргумента. Аргумент file принимает строку, в которой содержится путь к файлу. Второй аргумент, mode, позволяет указать режим, в котором необходимо работать с файлом. По умолчанию этот аргумент принимает значение «rt», с которым, и с некоторыми другими, можно ознакомиться в таблице ниже
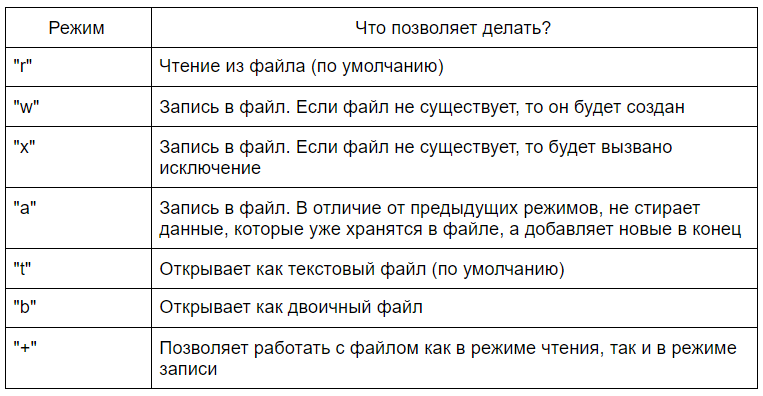
Эти режимы могут быть скомбинированы. Например, «rb» открывает двоичный файл для чтения. Комбинируя «r+» или «w+» можно добиться открытия файла в режиме и чтения, и записи одновременно с одним отличием — первый режим вызовет исключение, если файла не существует, а работа во втором режиме в таком случае создаст его.
Начать саму работу с файлом можно с помощью объекта класса io.TextIOWrapper, который возвращается функцией open(). У этого объекта есть несколько атрибутов, через которые можно получить информацию
name— название файла;mode— режим, в котором этот файл открыт;closed— возвращаетTrue, если файл был закрыт.
По завершении работы с файлом его необходимо закрыть при помощи метода close()
f = open("examp.le", "w")
// работа с файлом
f.close()Однако более pythonic way стиль работы с файлом встроенными средствами заключается в использовании конструкции with .. as .., которая работает как менеджер создания контекста. Написанный выше пример можно переписать с ее помощью
with open("examp.le", "w") as f:
// работа с файломГлавное отличие заключается в том, что python самостоятельно закрывает файл, и разработчику нет необходимости помнить об этом. И бонусом к этому не будут вызваны исключения при открытии файла (например, если файл не существует).
Чтение из файла
При открытии файла в режимах, допускающих чтение, можно использовать несколько подходов.

Для начала можно прочитать файл целиком и все данные, находящиеся в нем, записать в одну строку.
with open("examp.le", "r") as f:
text = f.read()Используя эту функцию с целочисленным аргументом, можно прочитать определенное количество символов.
with open("examp.le", "r") as f:
part = f.read(16)При этом будут получены только первые 16 символов текста. Важно понимать, что при применении этой функции несколько раз подряд будет считываться часть за частью этого текста — виртуальный курсор будет сдвигаться на считанную часть текста. Его можно сдвинуть на определенную позицию, при необходимости воспользовавшись методом seek().
with open("examp.le", "r") as f: # 'Hello, world!'
first_part = f.read(8) # 'Hello, w'
f.seek(4)
second_part = f.read(8) # 'o, world'Другой способ заключается в считывании файла построчно. Метод readline() считывает строку и, также как и с методом read(), сдвигает курсор — только теперь уже на целую строку. Применение этого метода несколько раз будет приводить к считыванию нескольких строк. Схожий с этим способом, другой метод позволяет прочитать файл целиком, но по строкам, записав их в список. Этот список можно использовать, например, в качестве итерируемого объекта в цикле.
with open("examp.le", "r") as f:
for line in f.readlines():
print(line)Однако и здесь существует более pythonic way. Он заключается в том, что сам объект io.TextIOWrapper имеет итератор, возвращающий строку за строкой. Благодаря этому нет необходимости считывать файл целиком, сохраняя его в список, а можно динамически по строкам считывать файл. И делать это лаконично.
with open("examp.le", "r") as f:
for line in f:
print(line)Запись в файл
Функциональность внесения данных в файл не зависит от режима — добавление данных или перезаписывание файла. В выполнении этой операции также существует несколько подходов.
Самый простой и логичный — использование функции write()
with open("examp.le", "w") as f:
f.write(some_string_data)Важно, что в качестве аргумента функции могут быть переданы только строки. Если необходимо записать другого рода информацию, то ее необходимо явно привести к строковому типу, используя методы __str__(self) для объектов или форматированные строки.
Есть возможность записать в файл большой объем данных, если он может быть представлен в виде списка строк.
with open("examp.le", "w") as f:
f.writelines(list_of_strings)Здесь есть еще один нюанс, связанный с тем, что функции write() и writelines() автоматически не ставят символ переноса строки, и это разработчику нужно контролировать самостоятельно.
Существует еще один, менее известный, способ, но, возможно, самый удобный из представленных. И как бы не было странно, он заключается в использовании функции print(). Сначала это утверждение может показаться странным, потому что общеизвестно, что с помощью нее происходит вывод в консоль. И это правда. Но если передать в необязательный аргумент file объект типа io.TextIOWrapper, каким и является объект файла, с которым мы работаем, то поток вывода функции print() перенаправляется из консоли в файл.
with open("examp.le", "w") as f:
print(some_data, file=f)Сила такого подхода заключается в том, что в print() можно передавать не обязательно строковые аргументы — при необходимости функция сама их преобразует к строковому типу.
На этом знакомство с базовой функциональностью работы с файлами можно закончить. Вместе с этим стоит сказать, что возможности языка Python им не ограничивается. Существует большое количество библиотек, которые позволяют работать с файлами определенных типов, а также допускают более тесное взаимодействие с файловой системой. И в совокупности они предоставляют разработчикам легкий и комфортный способ работы с файлами.
В данном материале мы рассмотрим, как читать и вписывать данные в файлы на вашем жестком диске. В течение всего обучения, вы поймете, что выполнять данные задачи в Python – это очень просто. Начнем же.
Как читать файлы
Python содержит в себе функцию, под названием «open», которую можно использовать для открытия файлов для чтения. Создайте текстовый файл под названием test.txt и впишите:
|
This is test file line 2 line 3 this line intentionally left lank |
Вот несколько примеров того, как использовать функцию «открыть» для чтения:
|
handle = open(«test.txt») handle = open(r«C:Usersmikepy101bookdatatest.txt», «r») |
В первом примере мы открываем файл под названием test.txt в режиме «только чтение». Это стандартный режим функции открытия файлов. Обратите внимание на то, что мы не пропускаем весь путь к файлу, который мы собираемся открыть в первом примере. Python автоматически просмотрит папку, в которой запущен скрипт для text.txt. Если его не удается найти, вы получите уведомление об ошибке IOError. Во втором примере показан полный путь к файлу, но обратите внимание на то, что он начинается с «r». Это значит, что мы указываем Python, чтобы строка обрабатывалась как исходная. Давайте посмотрим на разницу между исходной строкой и обычной:
|
>>> print(«C:Usersmikepy101bookdatatest.txt») C:Usersmikepy101bookdata est.txt >>> print(r«C:Usersmikepy101bookdatatest.txt») C:Usersmikepy101bookdatatest.txt |
Как видно из примера, когда мы не определяем строку как исходную, мы получаем неправильный путь. Почему это происходит? Существуют определенные специальные символы, которые должны быть отображены, такие как “n” или “t”. В нашем случае присутствует “t” (иными словами, вкладка), так что строка послушно добавляет вкладку в наш путь и портит её для нас. Второй аргумент во втором примере это буква “r”. Данное значение указывает на то, что мы хотим открыть файл в режиме «только чтение». Иными словами, происходит то же самое, что и в первом примере, но более явно. Теперь давайте, наконец, прочтем файл!
Введите нижеизложенные строки в скрипт, и сохраните его там же, где и файл test.txt.
|
handle = open(«test.txt», «r») data = handle.read() print(data) handle.close() |
После запуска, файл откроется и будет прочитан как строка в переменную data. После этого мы печатаем данные и закрываем дескриптор файла. Следует всегда закрывать дескриптор файла, так как неизвестно когда и какая именно программа захочет получить к нему доступ. Закрытие файла также поможет сохранить память и избежать появления странных багов в программе. Вы можете указать Python читать строку только раз, чтобы прочитать все строки в списке Python, или прочесть файл по частям. Последняя опция очень полезная, если вы работаете с большими фалами и вам не нужно читать все его содержимое, на что может потребоваться вся память компьютера.
Давайте обратим внимание на различные способы чтения файлов.
|
handle = open(«test.txt», «r») data = handle.readline() # read just one line print(data) handle.close() |
Если вы используете данный пример, будет прочтена и распечатана только первая строка текстового файла. Это не очень полезно, так что воспользуемся методом readlines() в дескрипторе:
|
handle = open(«test.txt», «r») data = handle.readlines() # read ALL the lines! print(data) handle.close() |
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
После запуска данного кода, вы увидите напечатанный на экране список, так как это именно то, что метод readlines() и выполняет. Далее мы научимся читать файлы по мелким частям.
Как читать файл по частям
Самый простой способ для выполнения этой задачи – использовать цикл. Сначала мы научимся читать файл строку за строкой, после этого мы будем читать по килобайту за раз. В нашем первом примере мы применим цикл:
|
handle = open(«test.txt», «r») for line in handle: print(line) handle.close() |
Таким образом мы открываем файл в дескрипторе в режиме «только чтение», после чего используем цикл для его повторения. Стоит обратить внимание на то, что цикл можно применять к любым объектам Python (строки, списки, запятые, ключи в словаре, и другие). Весьма просто, не так ли? Попробуем прочесть файл по частям:
|
handle = open(«test.txt», «r») while True: data = handle.read(1024) print(data) if not data: break |
В данном примере мы использовали Python в цикле, пока читали файл по килобайту за раз. Как известно, килобайт содержит в себе 1024 байта или символов. Теперь давайте представим, что мы хотим прочесть двоичный файл, такой как PDF.
Как читать бинарные (двоичные) файлы
Это очень просто. Все что вам нужно, это изменить способ доступа к файлу:
|
handle = open(«test.pdf», «rb») |
Мы изменили способ доступа к файлу на rb, что значит read-binaryy. Стоит отметить то, что вам может понадобиться читать бинарные файлы, когда вы качаете PDF файлы из интернете, или обмениваетесь ими между компьютерами.
Пишем в файлах в Python
Как вы могли догадаться, следуя логике написанного выше, режимы написания файлов в Python это “w” и “wb” для write-mode и write-binary-mode соответственно. Теперь давайте взглянем на простой пример того, как они применяются.
ВНИМАНИЕ: использование режимов “w” или “wb” в уже существующем файле изменит его без предупреждения. Вы можете посмотреть, существует ли файл, открыв его при помощи модуля ОС Python.
|
handle = open(«output.txt», «w») handle.write(«This is a test!») handle.close() |
Вот так вот просто. Все, что мы здесь сделали – это изменили режим файла на “w” и указали метод написания в файловом дескрипторе, чтобы написать какой-либо текст в теле файла. Файловый дескриптор также имеет метод writelines (написание строк), который будет принимать список строк, который дескриптор, в свою очередь, будет записывать по порядку на диск.
Выбирайте дешевые лайки на видео в YouTube на сервисе https://doctorsmm.com/. Здесь, при заказе, Вам будет предоставлена возможность подобрать не только недорогую цену, но и выгодные персональные условия приобретения. Торопитесь, пока на сайте действуют оптовые скидки!
Использование оператора «with»
В Python имеется аккуратно встроенный инструмент, применяя который вы можете заметно упростить чтение и редактирование файлов. Оператор with создает диспетчер контекста в Пайтоне, который автоматически закрывает файл для вас, по окончанию работы в нем. Посмотрим, как это работает:
|
with open(«test.txt») as file_handler: for line in file_handler: print(line) |
Синтаксис для оператора with, на первый взгляд, кажется слегка необычным, однако это вопрос недолгой практики. Фактически, все, что мы делаем в данном примере, это:
|
handle = open(«test.txt») |
Меняем на это:
|
with open(«test.txt») as file_handler: |
Вы можете выполнять все стандартные операции вводавывода, в привычном порядке, пока находитесь в пределах блока кода. После того, как вы покинете блок кода, файловый дескриптор закроет его, и его уже нельзя будет использовать. И да, вы все прочли правильно. Вам не нужно лично закрывать дескриптор файла, так как оператор делает это автоматически. Попробуйте внести изменения в примеры, указанные выше, используя оператор with.
Выявление ошибок
Иногда, в ходе работы, ошибки случаются. Файл может быть закрыт, потому что какой-то другой процесс пользуется им в данный момент или из-за наличия той или иной ошибки разрешения. Когда это происходит, может появиться IOError. В данном разделе мы попробуем выявить эти ошибки обычным способом, и с применением оператора with. Подсказка: данная идея применима к обоим способам.
|
try: file_handler = open(«test.txt») for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») finally: file_handler.close() |
В описанном выше примере, мы помещаем обычный код в конструкции try/except. Если ошибка возникнет, следует открыть сообщение на экране. Обратите внимание на то, что следует удостовериться в том, что файл закрыт при помощи оператора finally. Теперь мы готовы взглянуть на то, как мы можем сделать то же самое, пользуясь следующим методом:
|
try: with open(«test.txt») as file_handler: for line in file_handler: print(line) except IOError: print(«An IOError has occurred!») |
Как вы можете догадаться, мы только что переместили блок with туда же, где и в предыдущем примере. Разница в том, что оператор finally не требуется, так как контекстный диспетчер выполняет его функцию для нас.
Подведем итоги
С данного момента вы уже должны легко работать с файлами в Python. Теперь вы знаете, как читать и вносить записи в файлы двумя способами. Теперь вы сможете с легкостью ориентироваться в данном вопросе.

Являюсь администратором нескольких порталов по обучению языков программирования Python, Golang и Kotlin. В составе небольшой команды единомышленников, мы занимаемся популяризацией языков программирования на русскоязычную аудиторию. Большая часть статей была адаптирована нами на русский язык и распространяется бесплатно.
E-mail: vasile.buldumac@ati.utm.md
Образование
Universitatea Tehnică a Moldovei (utm.md)
- 2014 — 2018 Технический Университет Молдовы, ИТ-Инженер. Тема дипломной работы «Автоматизация покупки и продажи криптовалюты используя технический анализ»
- 2018 — 2020 Технический Университет Молдовы, Магистр, Магистерская диссертация «Идентификация человека в киберпространстве по фотографии лица»
Многим из нас знакома ситуация, когда компьютер оказывался завален тоннами беспорядочных файлов. Только что вы открывали большой zip-архив, спустя мгновение – файлы повсюду в этой директории, вперемешку с важными документами. Наверняка приходилось мучительно скучно сортировать эту свалку вручную? Чтобы облегчить подобные задачи, мы сейчас погрузимся в «умную» работу с файлами при помощи Python.
«Работай умнее, а не усерднее». Карл Баркс
Итак, приступим, вооружившись Python версии 3.4 или выше. Сначала пройдемся по модулю OS, а по ходу дела познакомимся еще с несколькими. Всё, что мы будем использовать, доступно в Python «с коробки», так что ничего дополнительно устанавливать не потребуется.
Генератор случайных файлов
Создадим папку ManageFiles, а внутри нее еще одну — RandomFiles. Дерево каталогов теперь должно выглядеть вот так:
ManageFiles/ | |_RandomFiles/
Чтобы поиграться с файлами, мы сгенерируем их случайным образом в директории RandomFiles. Создайте файл create_random_files.py в папке ManageFiles. Вот что должно получиться:
ManageFiles/ | |_ create_random_files.py |_RandomFiles/
Готово? Теперь поместите в файл следующий код, и перейдем к его рассмотрению:
import os
from pathlib import Path
import random
list_of_extensions = ['.rst', '.txt', '.md', '.docx', '.odt', '.html', '.ppt', '.doc']
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
for item in list_of_extensions:
# создать 20 случайных файлов для каждого расширения имени
for num in range(20):
# пусть имя файла начинается со случайного числа от 1 до 50
file_name = random.randint(1, 50)
file_to_create = str(file_name) + item
Path(file_to_create).touch()
Начиная с Python 3.4 мы получили pathlib, нашу маленькую волшебную палочку. Также мы импортируем функцию random для генерации случайных чисел, но ее мы посмотрим в действии чуть ниже.
Сперва создадим
список файловых расширений для формирования названий файлов. Не стесняйтесь
добавить туда свои варианты.
Далее мы переходим в папку RandomFiles и запускаем цикл. В нем мы просто говорим: возьми каждый элемент list_of_extensions и сделай с ним кое-что во внутреннем цикле 20 раз.
Теперь пришло время для импортированной функции random. Используем ее для производства случайных чисел от 1 до 50. Это просто не очень творческий способ побыстрее дать названия нашим тестовым файлам: к сгенерированному числу добавим расширение файла и получим что-то вроде 23.txt или 14.txt. И так 20 раз для каждого расширения. В итоге образуется беспорядок, достаточный для того, чтобы его было лень сортировать вручную.
Итак, запустим
наш генератор хаоса через терминал.
python create_random_files.py
Поздравляю,
теперь у нас полная папка неразберихи. Будем распутывать.
В той же директории, где create_random_files.py, создадим файл clean_up.py и поместим туда следующий код.
Способ 1
import os
import shutil
import glob
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
# получить список файлов в папке RandomFiles
files_to_group = []
for random_file in os.listdir('.'):
files_to_group.append(random_file)
# получить все расширения имен всех файлов
file_extensions = []
for our_file in files_to_group:
file_extensions.append(os.path.splitext(our_file)[1])
print(set(file_extensions))
file_types = set(file_extensions)
for type in file_types:
new_directory = type.replace(".", " ")
os.mkdir(new_directory) # создать папку с именем данного расширения
for fname in glob.glob(f'*.{type[1:]}'):
shutil.move(fname, new_directory)
Для этого импортируем еще две библиотеки: shutil и glob. Первая поможет перемещать файлы, а вторая – находить и систематизировать. Но обо всем по порядку.
Для начала получим список всех файлов в директории.
Здесь мы предполагаем, что у нас нет ни малейшего понятия о том, какие именно файлы лежат в этой папке. Вместо того, чтобы вписывать все расширения вручную и использовать лестницу инструкций if или switch, мы желаем, чтобы программа сама просмотрела каталог и определила, на какие типы можно разделить его содержание. Что, если бы там были файлы с десятками расширений или логи? Вы бы стали описывать их вручную?
Получив список всех
файлов, мы заходим в еще один цикл, чтобы извлечь расширения названий.
Обратите внимание на разделение строки:
os.path.splitext(our_file)[1]
Сейчас наша переменная our_file выглядит как-нибудь так: 5.docx. Когда разделим ее, получим следующее:
`('5', '.docx')`
Мы возьмем отсюда второй элемент по индексу [1], то есть .docx. Ведь по индексу [0] у нас располагается 5.
Таким образом, у нас имеется список всех файловых расширений в папке, в том числе повторяющихся. Чтобы оставить только уникальные элементы, преобразуем его во множество. К примеру, если бы этот список состоял исключительно из .docx, повторяющегося снова и снова, то в set остался бы всего один элемент.
# создать множество и присвоить его переменной file_types = set(file_extensions)
Заметим, что в списке типов файлов каждое расширение содержит . в начале. Если мы назовем так папки на UNIX-системе, то они будут скрытыми, что не входит в наши намерения.
Поэтому, итерируя
по нашему множеству, мы заменяем точку на пустую строку. И создаем папку с полученным
названием.
new_directory = type.replace(".", " ")
# наша директория теперь будет называться "docx"
Но чтобы переместить файлы, нам все еще нужно расширение .docx.
for fname in glob.glob(f'*.{type[1:]}')
Этим попросту отбираем все файлы, оканчивающиеся расширением .docx. Заметьте, что в f'*.{type[1:]}') нет пробелов.
Символ подстановки * обозначает, что подходит любое имя, если оно заканчивается на .docx. Поскольку мы уже включили точку в поиск, мы используем [1:], что значит «все после первого символа». В нашем примере это docx.
Что дальше?
Перемещаем любые файлы с данным расширением в директорию с тем же названием.
shutil.move(fname, new_directory)
Таким образом, как только в цикле создана папка для первого попавшегося файла с данным расширением, все последующие файлы будут отправлены в нее же. Все будет сгруппировано без повторения каталогов.
Способ 2
В качестве хитрого способа создать список в одну строку можно использовать генераторы.
import os
import shutil
import glob
# перейти в папаку RandomFiles
os.chdir('./RandomFiles')
# добавить все файлы в данной папке в список
all_files = [x for x in os.listdir('.')]
# создать множество расширений имен файлов в этой папке
file_types = set((os.path.splitext(f)[1] for f in all_files))
for ftype in file_types:
new_directory = ftype.replace(".", '')
os.mkdir(new_directory)
for fname in glob.glob(f'*.{ftype[1:]}'):
shutil.move(fname, new_directory)
Оба варианта сработают, и все ваши файлы будут отсортированы по расширению.
ManageFiles/
|
|_create_random_files.py
|_RandomFiles/
|_doc
|_docx
|_html
|_md
|_odt
|_ppt
Вот и все. Если вам когда-либо понадобится отсортировать файлы таким образом, вы сэкономите немало времени ?. Код упражнения доступен здесь.

Английский для программистов
Наш телеграм канал с тестами по английскому языку для программистов. Английский это часть карьеры программиста. Поэтому полезно заняться им уже сейчас
Скачать
×
Ловите шпору, которая поможет вам понять, как нужно работать с файлами в Python и успешно справится с ЕГЭ по информатике. Все режимы и параметры функции open, а так же функции для работы с файлами.
Жми сейв и наслаждайся!

Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter. Мы обязательно поправим!

Вам так же будет интересно
Личность в тексте
Вопрос, который может встретиться на ЕГЭ по литературе. Сохраняй себе скорее, чтобы не потерять!
…
Производная
Готовишься к ЕГЭ по математике? Лови готовую шпаргалку по производной!
Правила…
Теория игр
Мы подготовили для вас компактную, но супер информативную шпаргалку для ЕГЭ по информатике, которая…
![]()
[ Сборник задач ]
Тема 14. Работа с файлами


![]()
Контент: Вопросы (5шт) + задачи (5шт)
Оглавление
Введение
Взаимодействие с файлами разных типов в Python: текст, картинки, таблицы. Разные режимы открытия документов: на чтение, запись, дозапись. Основные модули для работы с файлами.
Перейти
Вопросы и ответы
5 вопросов по теме «Работа с файлами» + ответы
Перейти
Условия задач
5 задач по теме двух уровней сложности: Базовый и *Продвинутый
Перейти
Решения задач
Приводим код решений указанных выше задач
Перейти

Введение
Python позволяет оперировать разными типами документов: текстовыми в любом формате, графическими, медиа, табличными и json. Для этого имеются соответствующие модули и пакеты (так встроенные, так и те, которые необходимо дополнительно установить), а также ряд функций.
При работе с файлами в Python используется ряд функций и методов:
— функция open() — открывает файл для чтения, записи, добавления нового содержимого. Может принимать дополнительные параметры: для задания режима открытия, указания кодировки, вывода ошибок и др. Возвращает дескриптор файла, который обязательно нужно закрыть, иначе файл останется в памяти. Дескриптор в данном случае представляет собой путь к документу в виде строки;
— функция close() — закрывает файловый объект;
— инструкция with (позволяет автоматически закрывать файловый объект после работы с ним);
— метод read() — для чтения содержимого документа;
— метод readlines() — преобразует все строки файла в список;
— метод readline() — построчно выводит данные файла (удобно при работе с массивными документами);
— метод write() — записывает новую информацию в файл;
— функция rename() из модуля os — переименовывает документ и др.
При решении заданий потребуются следующие знания:
- Способы открытия файлов в разных режимах;
- Варианты задания кодировок;
- Методы чтения содержимого документов;
- Инструменты для записи файлов;
- Популярные библиотеки для работы с файлами (csv, json, Pillow и др.).
Читайте также

Вопросы по теме «Работа с файлами»
Существует 2 основных варианта открытия текстового документа:
- При помощи функции open() – дополнительно требуется закрыть файл после работы с ним, иначе он останется в памяти;
- С использованием контекстного менеджера with – закрывать документ не требуется, так как это произойдет автоматически. Синтаксис следующий:
Синтаксис
—
with open(‘файл’, ‘режим, ‘кодировка’) as {имя файлового объекта}:
____# Осуществляем чтение или запись данных
# Здесь файловый объект уже закрыт и удален из памяти
Приведем пример открытия условного файла article.txt, находящегося в текущей папке проекта.
Пример – IDE
—
# Открываем файл
text = open(‘article.txt’, ‘r’, encoding=’utf-8′)
# Работаем с ним
…
# Не забываем закрыть
text.close()
Пример – IDE
—
with open(‘article.txt’, ‘r’, encoding=’utf-8′) as text:
____# Работаем с файлом
____…
# Здесь он уже будет закрыт автоматически
…
Важно помнить о том, что следует указывать кодировку, чтобы не получилось так, что вместо понятного текста вы получаете набор кракозябр.
Функция open() позволяет как читать, так и записывать данные в файл. Существует несколько режимов, которые передаются вторым параметром:
– r – открытие документа на чтение;
– w – возможность записи в файл (все старые данные будут уничтожены), а если его не существует, он то предварительно будет создан;
– + — одновременные режимы чтения и записи;
– a – возможность дозаписывать содержимое документа;
– x – запись в существующий файл (с удалением старого содержимого), в противном случае возникнет ошибка;
– t – открытие документа в текстовом режиме;
– b – открытие документа в байтовом режиме.
По умолчанию используется значение rt, т.е. документ открывается на чтение в виде текста.
Функция print() позволяет не только выводить информацию в терминал, но и записывать ее в файл. Для этого применяется ключевой аргумент file. Основное удобство (по сравнению с функцией write()) заключается в том, что перенос на новую строку осуществляется автоматически.
Пример – IDE
—
with open(‘article.txt’, ‘w’, encoding=’utf-8′) as text:
____print(‘Доброго времени’, file=text)
____print(‘Пора прощаться’, file=text)
В результате получаем две строчки в документе article.txt:
Содержимое файла article.txt
—
Доброго времени
Пора прощаться
Встроенный модуль os позволяет работать с операционной системой и ее файлами. Он выводит не только сведения о системе, но и дает возможность создавать папки, проверять существование директорий и файлов на диске, переименовывать документы. Важно и то, что большая часть функций библиотеки поддерживается всеми операционками: хоть Windows, хоть Linux. Опишем 3 объекта из модуля:
– os.name – демонстрирует имя операционной системы;
– os.mkdir() – создает папку в определенной директории, если ее не существует;
– os.listdir() – выводит содержимое папки (как файлы, так и директории).
Пример – Интерактивный режим
—
>>> import os
>>> os.name
nt
>>> os.mkdir(‘temporary’)
>>> os.listdir(‘.’)
[‘.git’, ‘.idea’, ‘.vscode’, ‘temporary’, ‘test.csv’, ‘test.txt’]
Pillow – библиотека, созданная в 2009 году для удобной работы с изображениями. Помимо основных графических форматов имеется поддержка и специфических (psd, pdf, eps, tiff и др.).
Пакет позволяет осуществлять следующие операции:
- Получать полную информацию о файле (размеры, гистограмму цветов, exif-данные, цветовой режим);
- Менять картинки (обрезать, уменьшать-увеличивать, переводить в другую палитру, поворачивать и отображать, конвертировать);
- Накладывать фильтры (размытия, усиления резкости, сглаживания краев и др.);
- Создавать собственные рисунки (от простых геометрических фигур до сложнокомпозиционных работ);
- Наносить текст (любого цвета в любое место);
- Сохранять новые файлы в нужную директорию.
Основное удобство заключается в том, что изображения с легкостью обрабатываются пакетно, что позволяет привести их к одному виду, размеру, понятному наименованию. Вручную такие операции займут в сотни и тысячи раз больше времени.

Задачи по теме «Работа с файлами»

Решение
Задача 1. Базовый уровень
Напишите функцию read_last(lines, file), которая будет открывать определенный файл file и выводить на печать построчно последние строки в количестве lines (на всякий случай проверим, что задано положительное целое число).
Протестируем функцию на файле «article.txt» со следующим содержимым:
Вечерело
Жужжали мухи
Светил фонарик
Кипела вода в чайнике
Венера зажглась на небе
Деревья шумели
Тучи разошлись
Листва зеленелаТак как дополнительные символы показывать нам не требуются (переносы строк), выводить их на печать не будем.
def read_last(lines, file):
if lines > 0:
with open(file, encoding='utf-8') as text:
file_lines = text.readlines()[-lines:]
for line in file_lines:
print(line.strip())
else:
print('Количество строк может быть только целым положительным')
# Тесты
read_last(3, 'article.txt')
read_last(-5, 'article.txt')Деревья шумели
Тучи разошлись
Листва зеленела
Количество строк может быть только целым положительнымТеперь данную библиотеку может скачать любой пользователь и без проблем импортировать ее в свой проект, получив легкий и удобный доступ к 6-ти созданным нами функциям.
Задача 2. Базовый уровень
Выберите любую папку на своем компьютере, имеющую вложенные директории.
Выведите на печать в терминал ее содержимое, как и всех подкаталогов при помощи функции print_docs(directory).Проход по все каталогам и файлам в определенной директории можно осуществить при помощи функции walk() модуля os. Для примера возьмем следующую папку: C:/Program Files/Classic Shell.
import os
def print_docs(directory):
all_files = os.walk(directory)
for catalog in all_files:
print(f'Папка {catalog[0]} содержит:')
print(f'Директории: {", ".join([folder for folder in catalog[1]])}')
print(f'Файлы: {", ".join([file for file in catalog[2]])}')
print('-' * 40)
print_docs('C:/Program Files/Classic Shell')Папка C:/Program Files/Classic Shell содержит:
Директории: Skins
Файлы: ClassicExplorer32.dll, ClassicExplorer64.dll, ClassicExplorerSettings.exe, ClassicIEDLL_32.dll, …
----------------------------------------
Папка C:/Program Files/Classic Shell/Skins содержит:
Директории:
Файлы: Classic Skin.skin, Classic Skin.skin7, …Задача 3. Базовый уровень
Документ «article.txt» содержит следующий текст:
Вечерело
Жужжали мухи
Светил фонарик
Кипела вода в чайнике
Венера зажглась на небе
Деревья шумели
Тучи разошлись
Листва зеленела
Требуется реализовать функцию longest_words(file), которая выводит слово, имеющее максимальную длину (или список слов, если таковых несколько).
Сначала извлечем всё содержимое документа, а потом найдем слова с максимальным количеством символов.
def longest_words(file):
with open(file, encoding='utf-8') as text:
words = text.read().split()
max_length = len(max(words, key=len))
sought_words = [word for word in words if len(word) == max_length]
if len(sought_words) == 1:
return sought_words[0]
return sought_words
print(longest_words('article.txt'))Задача 4. Продвинутый уровень
Требуется создать csv-файл «rows_300.csv» со следующими столбцами:
– № - номер по порядку (от 1 до 300);
– Секунда – текущая секунда на вашем ПК;
– Микросекунда – текущая миллисекунда на часах.
На каждой итерации цикла искусственно приостанавливайте скрипт на 0,01 секунды.Для работы с файлами подобного текстового формата потребуется встроенная в Python библиотека csv.
import csv
import datetime
import time
with open('rows_300.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['№', 'Секунда ', 'Микросекунда'])
for line in range(1, 301):
writer.writerow([line, datetime.datetime.now().second, datetime.datetime.now().microsecond])
time.sleep(0.01)
В итоге создастся требуемый файл. Приведем первые строки его содержимого:
Содержимое файла rows_300.csv
№,Секунда ,Микросекунда
1,51,504807
2,51,515807
3,51,526819
4,51,537817
5,51,548800
6,51,558817
…Задача 5. Продвинутый уровень
При помощи библиотеки Pillow в директории circles (создайте ее во время выполнения функции) нарисуйте и сохраните 100 кругов радиусом 300 пикселей случайных цветов в формате jpg на белом фоне (каждый круг - отдельный файл). Для этого напишите функцию circles_generator(num_of_circles=100).В первую очередь требуется установка модуля Pillow:
Осталось только случайным образом генерировать цвета в палитре RGB и воспользоваться классами Image, ImageDraw из установленной библиотеки. Чтобы нарисовать круг, нужно применить метод ellipse() и задать координаты точек, соответствующие квадрату.
from random import randint
import os
from PIL import Image, ImageDraw
def circles_generator(num_of_circles=100):
if not os.path.exists('circles'):
os.mkdir('circles')
for pic_name in range(1, num_of_circles + 1):
img = Image.new('RGB', (600, 600), (255, 255, 255))
draw = ImageDraw.Draw(img)
draw.ellipse((0, 0, 600, 600), fill=(randint(0, 255), randint(0, 255), randint(0, 255)))
img.save(f'circles/{pic_name}.jpg', quality=85)
circles_generator()В результате выполнения скрипта в папке circles появится 100 картинок кругов одинакового размера. При повторном вызове программы ошибки не будет, так как мы создаем папку лишь в том случае, если ее нет.
Как вам материал?


Читайте также
Для решения задачи (25) полезно уметь пользоваться (f)-строками — форматированными выражениями, содержащими поля замены. Форматированные (f)-строки имеют вид f'<текст >{объект}< текст>’. Поля замены ограничиваются фигурными скобками, и значения в них подставляются во время выполнения программы.
Например, фрагменты программ:
print(‘Решать задания ЕГЭ мне помогают материалы ЯКласс!’)
print(f’Решать задания ЕГЭ мне помогают материалы ЯКласс!’)
будут выполняться одинаково, хотя в верхней строке обычное форматирование, а во второй — (f)-строка. Обратим на это внимание в следующем примере.
![]()
Рис. (1). Пример вывода

Рис. (2). Результат работы программы (1)
Для аккуратного форматирования придётся воспользоваться разделителем sep(=») и вставкой дополнительных пробелов в текст для того, чтобы избавиться от автоматически расставляемых пробелов на месте запятых в функции print.
Сравни результат работы с результатом работы (f)-строки:
![]()
Рис. (3). Пример вывода (f)-строки

Рис. (4). Результат работы программы (2)
Конечно, этим не исчерпываются возможности (f)-строк.
Рассмотрим задачу на поиск делителей числа.
Пример (1)
Для некоторого случайного числа в интервале ([4,12300]) подсчитай количество нетривиальных делителей и выведи их.
Решение

Рис. (5). Программа (1)

Рис. (6). Результат работы программы (3)
Обрати внимание на оформление вывода. Результаты работы программы форматированы как (f)-строки. В качестве объекта в фигурных скобках записана стандартная функция len от другой функции mult. Одна из этих функций составлена пользователем и описана здесь же в программе. Кроме использования вычислений в (f)-строке мы также можем форматировать нужные нам строки.
Пример (2)
Даны символы «e», «c», «t», «f», «j», «k», «y». Сколько различных имён файлов, соответствующих маске (1?23.?x?), можно составить из предложенных символов? Сколько из них будут иметь расширение «txt» или «exe»?

Рис. (7). Программа (2)
Обрати внимание: для контроля за работой программы мы вывели на печать имена файлов с заданными расширениями.

Рис. (8). Результат работы программы (4)
Разбор досрочного варианта (2022)
Назовём маской числа последовательность цифр в которой также могут встречаться следующие символы:
-
символ «?» означает ровно одну произвольную цифру;
-
символ «*» означает любую последовательность цифр произвольной длины; в том числе «*» может задавать и пустую последовательность.
Среди натуральных чисел, не превышающих (10**9), найди все числа, соответствующие маске (12345?6?8) и делящиеся на (17) без остатка.
В ответе запиши в первом столбце таблицы все найденные числа в порядке возрастания, а во втором столбце — соответствующие им частные от деления на (17).
Здесь полем замены будут цифры, занимающие места «?».

Рис. (9). Программа (3)

Рис. (10). Результат работы программы (5)
Для решения задач с применением масок числа полезно знать работу функции product модуля itertools.
В условии задачи досрочного варианта упоминается, что в маске может находиться «*», а это набор символов любой длины, в том числе и нулевой.
Функция product модуля itertools сформирует нам необходимую комбинацию символов для замены «*».
Рассмотрим пример её работы.
Пример (3)
Составь все возможные пары из элементов строк (‘0123’) и (‘abcd’) — такие, чтобы первый элемент был из числовой строки, а следующий — из текстовой. (Множество таких пар элементов называется декартовым произведением первой и второй из заданных строк.)

Рис. (11). Программа (4)
Мы получили список, состоящий из кортежей, первый элемент которых — из числовой строки, а второй — из текстовой.

Рис. (12). Результат работы программы (6)
Но для вставки вместо «*» нам нужно преобразовать кортежи, из которых состоит список, в строки.
Пример (3A)

Метод join преобразовал кортежи в строки.

Рис. (13). Результат работы программы (7)
Если необходимо составить комбинации пар, или троек, или иного количества символов одного множества, то необходимо задать параметр repeat для функции product.
Пример (3B)
Составь таблицу истинности логической функции
((x→y)≡(z→w))∨(x∧w).

Рис. (14). Программа (5)

Рис. (15). Результат работы программы (8)
Пример (3C)

Рис. (16). Программа (6)

Рис. (17). Результат работы программы (9)
Вот эти строки уже можно вставлять на место «*».
Рассмотрим ещё одно задание из ЕГЭ прошлых лет.
Пример (4)
Определи, какое из указанных имён файлов удовлетворяет маске (‘?vi*r.?xt’).
1) vir.txt
2) ovir.txt
3) ovir.xt
4) virr.txt
Задание решалось вручную, и мы можем составить программу и сопоставить ответ, полученный программой, с ручными расчётами.

Рис. (18). Программа (7)
Эта статья посвящена работе с файлами (вводу/выводу) в Python: открытие, чтение, запись, закрытие и другие операции.
Файл — это всего лишь набор данных, сохраненный в виде последовательности битов на компьютере. Информация хранится в куче данных (структура данных) и имеет название «имя файла» (filename).
В Python существует два типа файлов:
- Текстовые
- Бинарные
Текстовые файлы
Это файлы с человекочитаемым содержимым. В них хранятся последовательности символов, которые понимает человек. Блокнот и другие стандартные редакторы умеют читать и редактировать этот тип файлов.
Текст может храниться в двух форматах: (.txt) — простой текст и (.rtf) — «формат обогащенного текста».
Бинарные файлы
В бинарных файлах данные отображаются в закодированной форме (с использованием только нулей (0) и единиц (1) вместо простых символов). В большинстве случаев это просто последовательности битов.
Они хранятся в формате .bin.
Любую операцию с файлом можно разбить на три крупных этапа:
- Открытие файла
- Выполнение операции (запись, чтение)
- Закрытие файла
Открытие файла
Метод open()
В Python есть встроенная функция open(). С ее помощью можно открыть любой файл на компьютере. Технически Python создает на его основе объект.
Синтаксис следующий:
f = open(file_name, access_mode)
Где,
file_name= имя открываемого файлаaccess_mode= режим открытия файла. Он может быть: для чтения, записи и т. д. По умолчанию используется режим чтения (r), если другое не указано. Далее полный список режимов открытия файла
| Режим | Описание |
|---|---|
| r | Только для чтения. |
| w | Только для записи. Создаст новый файл, если не найдет с указанным именем. |
| rb | Только для чтения (бинарный). |
| wb | Только для записи (бинарный). Создаст новый файл, если не найдет с указанным именем. |
| r+ | Для чтения и записи. |
| rb+ | Для чтения и записи (бинарный). |
| w+ | Для чтения и записи. Создаст новый файл для записи, если не найдет с указанным именем. |
| wb+ | Для чтения и записи (бинарный). Создаст новый файл для записи, если не найдет с указанным именем. |
| a | Откроет для добавления нового содержимого. Создаст новый файл для записи, если не найдет с указанным именем. |
| a+ | Откроет для добавления нового содержимого. Создаст новый файл для чтения записи, если не найдет с указанным именем. |
| ab | Откроет для добавления нового содержимого (бинарный). Создаст новый файл для записи, если не найдет с указанным именем. |
| ab+ | Откроет для добавления нового содержимого (бинарный). Создаст новый файл для чтения записи, если не найдет с указанным именем. |
Пример
Создадим текстовый файл example.txt и сохраним его в рабочей директории.

Следующий код используется для его открытия.
f = open('example.txt','r') # открыть файл из рабочей директории в режиме чтения
fp = open('C:/xyz.txt','r') # открыть файл из любого каталога
В этом примере f — переменная-указатель на файл example.txt.
Следующий код используется для вывода содержимого файла и информации о нем.
>>> print(*f) # выводим содержимое файла
This is a text file.
>>> print(f) # выводим объект
<_io.TextIOWrapper name='example.txt' mode='r' encoding='cp1252'>
Стоит обратить внимание, что в Windows стандартной кодировкой является cp1252, а в Linux — utf-08.
Закрытие файла
Метод close()
После открытия файла в Python его нужно закрыть. Таким образом освобождаются ресурсы и убирается мусор. Python автоматически закрывает файл, когда объект присваивается другому файлу.
Существуют следующие способы:
Способ №1
Проще всего после открытия файла закрыть его, используя метод close().
f = open('example.txt','r')
# работа с файлом
f.close()
После закрытия этот файл нельзя будет использовать до тех пор, пока заново его не открыть.
Способ №2
Также можно написать try/finally, которое гарантирует, что если после открытия файла операции с ним приводят к исключениям, он закроется автоматически.
Без него программа завершается некорректно.
Вот как сделать это исключение:
f = open('example.txt','r')
try:
# работа с файлом
finally:
f.close()
Файл нужно открыть до инструкции
try, потому что если инструкцияopenсама по себе вызовет ошибку, то файл не будет открываться для последующего закрытия.
Этот метод гарантирует, что если операции над файлом вызовут исключения, то он закроется до того как программа остановится.
Способ №3
Инструкция with
Еще один подход — использовать инструкцию with, которая упрощает обработку исключений с помощью инкапсуляции начальных операций, а также задач по закрытию и очистке.
В таком случае инструкция close не нужна, потому что with автоматически закроет файл.
Вот как это реализовать в коде.
with open('example.txt') as f:
# работа с файлом
Чтение и запись файлов в Python
В Python файлы можно читать или записывать информацию в них с помощью соответствующих режимов.
Функция read()
Функция read() используется для чтения содержимого файла после открытия его в режиме чтения (r).
Синтаксис
file.read(size)
Где,
file= объект файлаsize= количество символов, которые нужно прочитать. Если не указать, то файл прочитается целиком.
Пример
>>> f = open('example.txt','r')
>>> f.read(7) # чтение 7 символов из example.txt
'This is '
Интерпретатор прочитал 7 символов файла и если снова использовать функцию read(), то чтение начнется с 8-го символа.
>>> f.read(7) # чтение следующих 7 символов
' a text'
Функция readline()
Функция readline() используется для построчного чтения содержимого файла. Она используется для крупных файлов. С ее помощью можно получать доступ к любой строке в любой момент.
Пример
Создадим файл test.txt с нескольким строками:
This is line1.
This is line2.
This is line3.
Посмотрим, как функция readline() работает в test.txt.
>>> x = open('test.txt','r')
>>> x.readline() # прочитать первую строку
This is line1.
>>> x.readline(2) # прочитать вторую строку
This is line2.
>>> x.readlines() # прочитать все строки
['This is line1.','This is line2.','This is line3.']
Обратите внимание, как в последнем случае строки отделены друг от друга.
Функция write()
Функция write() используется для записи в файлы Python, открытые в режиме записи.
Если пытаться открыть файл, которого не существует, в этом режиме, тогда будет создан новый.
Синтаксис
file.write(string)
Пример
Предположим, файла xyz.txt не существует. Он будет создан при попытке открыть его в режиме чтения.
>>> f = open('xyz.txt','w') # открытие в режиме записи
>>> f.write('Hello n World') # запись Hello World в файл
Hello
World
>>> f.close() # закрытие файла
Переименование файлов в Python
Функция rename()
Функция rename() используется для переименовывания файлов в Python. Для ее использования сперва нужно импортировать модуль os.
Синтаксис следующий.
import os
os.rename(src,dest)
Где,
src= файл, который нужно переименоватьdest= новое имя файла
Пример
>>> import os
>>> # переименование xyz.txt в abc.txt
>>> os.rename("xyz.txt","abc.txt")
Текущая позиция в файлах Python
В Python возможно узнать текущую позицию в файле с помощью функции tell(). Таким же образом можно изменить текущую позицию командой seek().
Пример
>>> f = open('example.txt') # example.txt, который мы создали ранее
>>> f.read(4) # давайте сначала перейдем к 4-й позиции
This
>>> f.tell() # возвращает текущую позицию
4
>>> f.seek(0,0) # вернем положение на 0 снова
Методы файла в Python
file.close() |
закрывает открытый файл |
file.fileno() |
возвращает целочисленный дескриптор файла |
file.flush() |
очищает внутренний буфер |
file.isatty() |
возвращает True, если файл привязан к терминалу |
file.next() |
возвращает следующую строку файла |
file.read(n) |
чтение первых n символов файла |
file.readline() |
читает одну строчку строки или файла |
file.readlines() |
читает и возвращает список всех строк в файле |
| file.seek(offset[,whene]) | устанавливает текущую позицию в файле |
file.seekable() |
проверяет, поддерживает ли файл случайный доступ. Возвращает True, если да |
file.tell() |
возвращает текущую позицию в файле |
file.truncate(n) |
уменьшает размер файл. Если n указала, то файл обрезается до n байт, если нет — до текущей позиции |
file.write(str) |
добавляет строку str в файл |
file.writelines(sequence) |
добавляет последовательность строк в файл |